Письмо
04 - Введение (продолжение)
|
Аналогичные рассуждения можно привести и в отношении программных систем. Если бы тот, кто нуждается в сервисе, предоставляемом системой, был в единственном числе, то форма прямых или косвенных вызовов была бы оптимальным решением. Но, предположив большее число «пациентов», нужно предположить и возможную неэффективность данной формы связи. В отличие от вызовов, сообщения не попадают непосредственно к обработчику. Сначала они помещаются в очередь, где порядок их обработки может быть изменён с целью оптимального исполнения всей совокупности поступивших сообщений. В качестве примера можно рассмотреть работу некоторых подсистем операционной системы. Пусть нам необходимо спроектировать менеджер памяти. В многозадачной операционной системе память, как правило, сильно фрагментирована. Для учёта свободных и занятых блоков или страниц существуют различного рода таблицы. При получении запроса на выделение блока памяти менеджер должен выполнить просмотр этих таблиц и найти либо наиболее подходящий блок, либо первый блок не меньшего размера. Когда количество запросов на выделение и освобождение памяти возрастает, то растёт и совокупное время, затрачиваемое на просмотр таблиц. Простая оптимизация очереди запросов позволит, во-первых, удовлетворить часть запросов на выделение памяти за счёт запросов на освобождение памяти. Во-вторых, можно ускорить обработку запросов посредством простой сортировки очереди, например, в порядке возрастания или убывания размеров запрашиваемых блоков. В этом случае можно удовлетворить все запросы за один проход по системным таблицам. Учитывая то, что количество фрагментов, как правило, существенно больше, чем число запросов поступающих за фиксированный промежуток времени, такая оптимизация может существенно ускорить работу менеджера памяти. В качестве другого примера можно рассмотреть работу дисковой подсистемы. Пусть несколько задач будут одновременно что-то писать на диск и/или читать с диска. Очевидно, что основное время будет тратиться на пробег головки к требуемой области диска. Если предположить, что чтение и/или запись производятся в произвольных частях диска, и подсистема реагирует на каждый запрос, то среднее время исполнения запроса будет примерно равно N*T/2, где N – это число запросов за единицу времени, а T – время пробега по всему диску. Отказ от вызовов позволит ставить запросы в очередь. Сортировка очереди даёт возможность обслужить всё множество запросов за один пробег головки по диску, а, следовательно, среднее время исполнения запроса будет находиться в пределах - T/N. 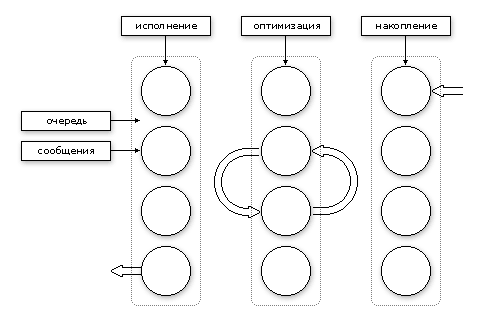
Наверное, имеет смысл отметить, что оптимизация очереди, обработка сообщений, которые в ней находятся, и регистрация новых сообщений - это различные по своей сути процессы, и они могут протекать параллельно. Для того, что сделать возможной параллельную работу можно использовать несколько очередей. Например, в то время, пока объект-обработчик обслуживает сообщения из первой очереди, сообщения во второй очереди оптимизируются, а третья очередь принимает новые сообщения. После того, как обслужены все сообщения из первой очереди (очередь пуста), на обработку поступает вторая очередь сообщений, третья очередь попадает под оптимизацию, а новые сообщения поступают в первую очередь, и т.д. Таким образом, можно получить высокоэффективный конвейер по обработке сообщений, все участки которого работают параллельно. В отличие от этого, при использовании механизма прямых и/или косвенных вызовов выполнить оптимизацию запросов практически невозможно. Другая важная особенность механизма сообщений заключается в том, что источник сообщения и его получатель могут находиться на разных компьютерах. Это позволяет строить распределённые системы почти столь же просто, как и создавать приложения, работающие на одном компьютере. Функция диспетчеризации сообщений от источника к получателю является одним из сервисов объектной системы. Иными словами, можно утверждать, что объектная система, построенная на сообщениях, может быть с минимальными усилиями преобразована в распределённую среду в рамках локальной или Intranet сети. Это тоже важное условие при построении сложных систем. Системы, построенные на сообщениях, обладают большей гибкостью, чем системы, построенные на вызовах. Повышенная гибкость связана с возможностью перехвата и перенаправления сообщений, их предварительной обработкой, до того, как они поступят к получателю. Данное свойство может быть полезно, например, для того чтобы организовать проверку прав доступа источника сообщения к ресурсу, для проверки типов параметров запроса, для регистрации запросов, что очень помогает при отладке программных модулей и т.п. Отсюда можно сделать ещё один вывод, что системы, построенные на основе обмена сообщениями, обладают большей изолированностью участков кода. Применительно к объектным системам можно добавить, что при помощи сообщений поддерживается полная инкапсуляция. Разработчикам, использующим некий класс, достаточно иметь список сообщений, понимаемый данным классом. Но этот же механизм даёт возможность расширить понятие полиморфизма, то есть, не рассматривать его как часть механизма наследования. Не менее интересно и то, что сообщения можно создавать заранее. Возможно, что данное свойство может показаться несколько странным, но именно благодаря этому, возможно, не только конструировать схемы обработки, которые будут рассмотрены позже, но и создавать схемы-шаблоны. Под схемой подразумевается порядок диспетчеризации исходного сообщения к нескольким объектам, то есть разложение исходного сообщения на серию сообщений к другим объектам. Схема-шаблон – это виртуальная схема, которая может быть использована при создании новых классов и/или назначена непосредственно во время работы объекта. Возвращаясь к параллелизму, надо отметить, что параллелизм надо рассматривать на трёх уровнях. Первый уровень параллелизма основан на параллельном исполнении процессором нескольких машинных команд. Этот уровень с успехом используется при распараллеливании алгоритмов, позволяя значительно увеличивать скорость исполнения. Современные технологии, предлагаемые разработчиками процессоров, значительно расширяют возможности данного уровня параллелизма. Например, технология EPIC (Explicitly Parallel Instruction Coding) воплощённая фирмами Intel и Hewlett Packard в процессоре Itanium, является развитием идеи параллельного исполнения нескольких команд. Большое регистровое пространство с возможностью переименования регистров, создание и передача подпрограммам регистровых пулов позволяют параллельно исполнять не только отдельные машинные команды, но целые блоки операторов. Второй уровень параллелизма состоит в параллельном исполнении задач на одном или нескольких процессорах. Существующие двух- и четырёхпроцессорные компьютеры будут постепенно вытесняться компьютерами, имеющими значительно большее количество процессоров. Однако при существующей SMP (симметричные мультипроцессоры) технологии, основанной на общей разделяемой памяти с единым физическим адресным пространством, рост количества процессоров будет сдерживаться ограничениями, присущими этой технологии. Использование общей разделяемой памяти требует постоянного согласования одних и тех же данных (информации расположенной в некоторой физической области памяти) изменяемых различными процессорами. Это приводит к интенсивному обмену информацией между процессорами. Как следствие, процессоры должны соединяться по схеме каждый-с каждым с помощью высокоскоростных каналов. С ростом количества процессоров возрастает и время, требуемое на синхронизацию данных, возрастает и количество каналов, и сложность арбитража. Как правило, количество процессоров в SMP-системах не превышает 32. Следующий уровень состоит в переходе к системам с массовым параллелизмом (MPP-системы). Системы с массовым параллелизмом представляют собой вычислительные модули соединённые скоростными каналами связи. Каждый вычислительный модуль является либо отдельным процессором, либо SMP-системой. У каждого модуля есть своя собственная память, которая не разделяется с другими модулями. В силу этой особенности существует возможность выполнения разнородных задач на каждом из модулей при отсутствии взаимного влияния. Независимость задач исполняемых в различных MPP-модулях снижает необходимость в обмене информацией между модулями, поскольку исчезает потребность в регулярной синхронизации общих данных. Межзадачный обмен информацией происходит в виде обмена сообщениями (пакетами), и этот процесс напоминает взаимодействие компьютеров в сети. Объекты обладают важным, с точки зрения развития параллелизма, свойством, они представляют собой изолированные сущности. При правильном проектировании никакие два объекта не должны иметь пересечений ни по данным, ни по обслуживаемым ими ресурсам. Следовательно, благодаря объектной технологии можно существенно увеличить параллельность работы и осуществить переход к MPP системам. |